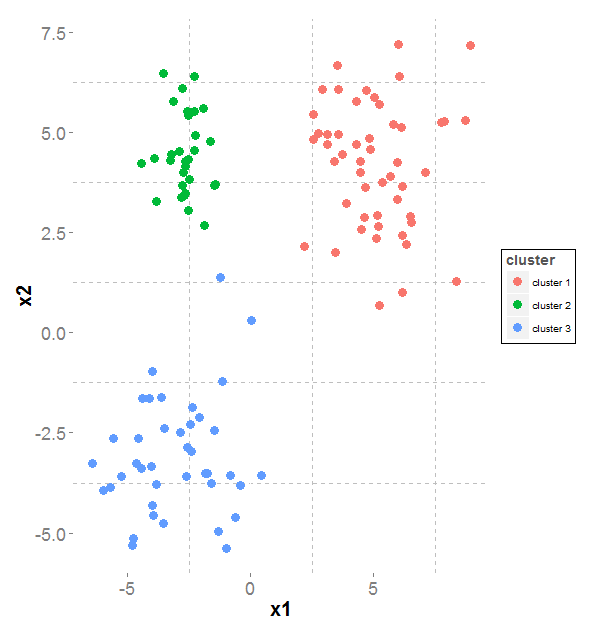
First of all, there is nothing magical with prediction, everybody can make a prediction. For instance, let's say we want to predict who will win the next game in
a sport competition. If you know that team A beat team B 7 times in their last 10 confrontations, you would say that there is 7 chances over 10 that team A win the next game.
So the probability that team A win knowing they are playing against B is 0.7, p(A|B) = 0.7. This a model. Sure there are many limits to this model and many more things to consider in order
to make a better prediction, for instance we could think of the location of the game (are they playing at home or outside), are the players from each team tired, and many more. What we want
is a model that can give us the probability to win for each team given many attributes (called variables). So here we want to measure the impact of the tiredness on the probability, the impact
of the location etc ... And to measure all of this, we need to have an history of observation. For instance we have seen from historical data that when a team is tired they have 10% less chance
win. So know p(A|B) = 0.6 if A is tired and p(A|B) = 0.8 if B is tired. That is what a linear regression model does: it gives weight to every variable in order to measure the how each variable
increases or decreases the winning probability
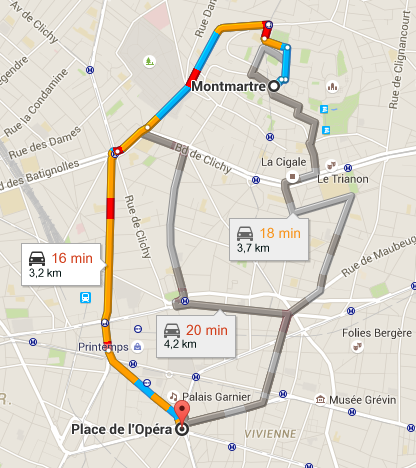
Let's take an other example that we will reuse later. Suppose we want to go from a point A to a point B and figure out which is the best path to do so. The first thing to do is to define best. It
is a question of time, a question of distance, the most beautiful, ... Let's choose time as our objective. In machine learning we often have a huge historic of past observation, so we can assume
that here we have thousand observations of people taking 10 differents path from A to B. We can measure how long it takes to go from A to B for each path, compute the mean and then we would be able
to tell which is the best path. This is a model. But maybe we would like to be more precise, maybe the best path is not the same in the morning that in the afternoon. So we compute again the mean
time for each path in the morning and in the afternoon and find the best path in the morning and the best path in the afternoon. This is an other model. But once again, we could be more precise.
Maybe the best path depend on the moment of the day, the day of the week, the week of the year, the month, the weather, roadworks ... The problem is that we may not have observation for all those
parameters for each road, so we cannot compute the mean time in each configuration. What we want is a model that measure the weight of each variable. As for sport, we want a model able to say:
if their is roadworks, the path is 10% longer, if it is early in the morning it is 20% shorter etc ... And all those weights are measurable because, even if we do not have observation for each
configuration, we do have observation for each variable. That's where machine learning is useful. If we have millions of observations and many variables, one human could compute everything
manually but this would be very long. On the other hand, the computer can do thos computation very quickly and test many different ways to model the output (here the time from A to B).
In supervised learning, we assume that a huge amount of past observations was available. But this is not always the case and having those observations can be very costly. For instance if you want
to predict if a medecine will have effect, it could be a very bad idea to test the medecine at random on millions of people ... Furthermore, when learning from past observation one can only learn
from what have been explored. For example, in the path example, if nobody took the road on a sunday it will be impossible to predict the impact of this day. Reinforcement Learning on the other hand
suppose no past observation at the begining.
Let's take again the path from A to B example. The only thing we know is that there are 10 differents path from A to B. And each time we want to take the road we have to choose a path. In
reinforcement learning it is called an action. But we don't want to take a path at random, we want it to be the quicker. In reinforcement learning we say that we want to minimize the regret,
the regret being the difference between the best path and the path we choose. But how to know the best path if we have no previous observation ? We have to explore ! That is we have to test
each path. Maybe you can see a problem here. We have to test each path, but we want to choose the best. This is called the exploration-exploitation dilemma. The exploration being we test each
path, the explotation being to choose the best path given the previous test. We can say that supervised learning proceed in two separates step:
- the first one is pure exploration, it is how we collect observations
- the seconde one is pure exploitation, we construct a model to tell us which one is the best path
But there much more better way to do so. If you took each path 1 time, you could rank each path from the best one to the worst one. But is the worst really the worst ? Maybe it is bad luck, it
was the longest this time because of an accident that time or something else. So you have to test it again to be sure it is the worst. But after a while, you want to stop to test the bad paths
and put more effort in exploration amoung the good paths to find the best.
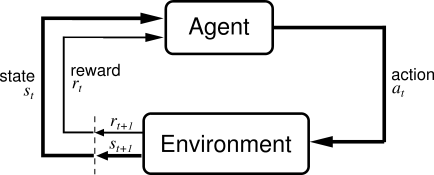
That is what reinforcement learning does: it defines a strategy to find the best action to perform in order to minimize the regret. This strategy being iteratative: the agent choose an action
and received a reward which depend on the environnement.
Unlike supervised learning, unsupervised learning does not have an output to predict, the goal is to create group of observations. For instance, one would like to group a list of news articles
in order to be able to present same by categories. We do not know in advance how many group of articles their are. Once again a human could do that. You take the first article read it, then read
the second one, if it seems similar to the first one you add it to the pile, if not you start a new pile. And do so until the last article is classify. But if their are millions of articles,
this could be a very long task for a human ... Unsupervised learning algorithm try to group observations that have similar variable and get groups as homogeneous as possible within each group and
as heterogeneous as possible between each group.